02 给 Toy Graph 加上多节点分支
02 给 Toy Graph 加上多节点分支
本章对应分支chapter-02-02
上一篇我们只跑通了一个最小链路:
START -> TOY_HELLO_NODE -> END
这一篇开始把它升级成真正有编排意味的多节点 Graph:
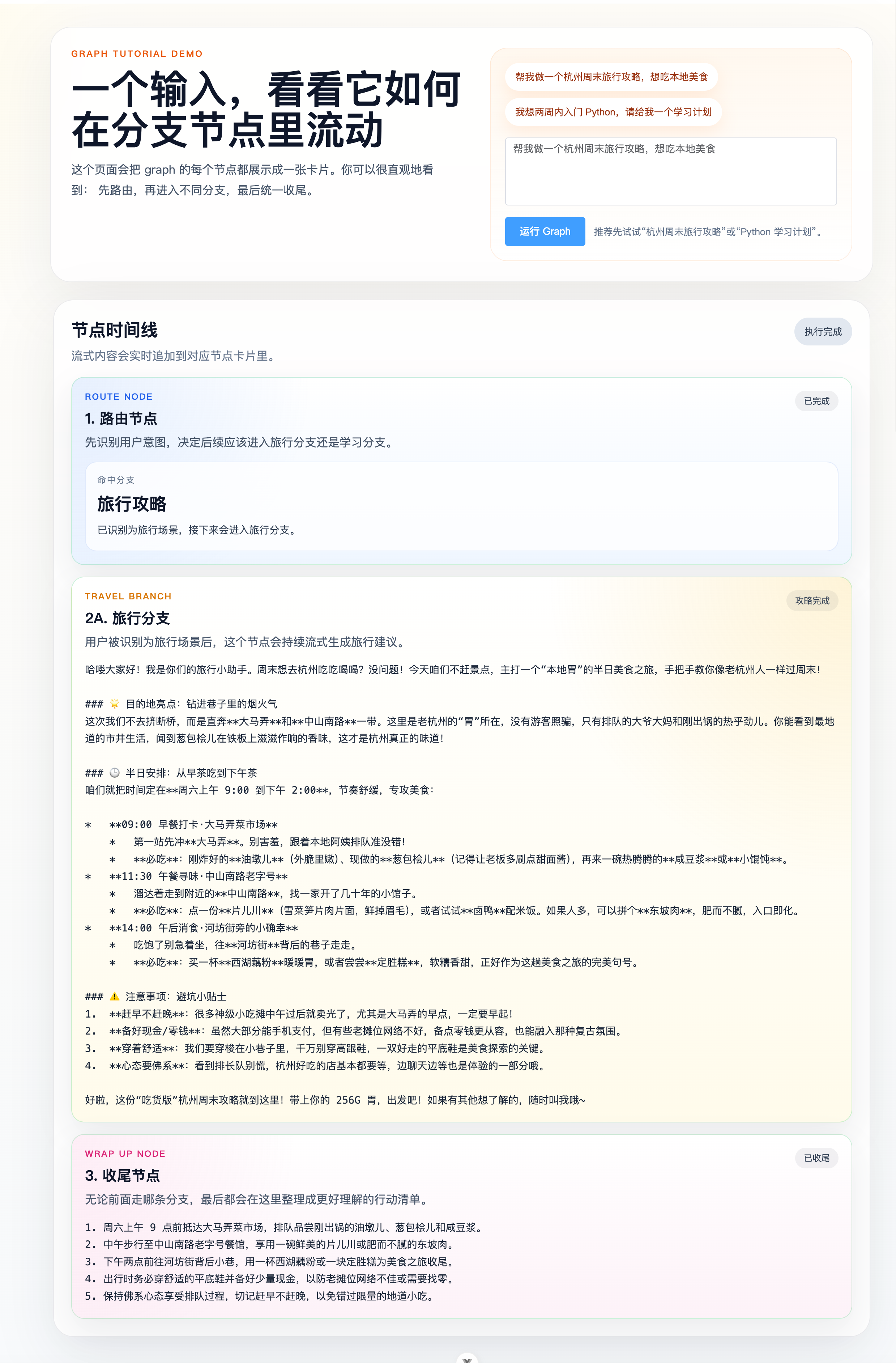
START -> ROUTE -> (TRAVEL_PLAN | STUDY_PLAN) -> WRAP_UP -> END
也就是说,用户输入不再直接交给一个节点处理到底,而是先做场景判断,再进入不同分支,最后统一收尾。
本文目标
- 理解多节点图是怎么从单链路演进出来的。
- 看懂
GraphConfiguration里条件分支是怎么声明的。 - 理解路由节点、分支节点、收尾节点之间的状态协作方式。
- 看懂前端为什么能把每个节点独立展示成时间线卡片。
改动位置
- 图规范:
data-agent-backend/src/main/kotlin/io/github/qifan777/server/graph/ToyGraphSpec.kt - 图配置:
data-agent-backend/src/main/kotlin/io/github/qifan777/server/graph/GraphConfiguration.kt - 条件边:
data-agent-backend/src/main/kotlin/io/github/qifan777/server/graph/edges/ToySceneBranchEdge.kt - 路由与业务节点:
ToySceneRouterNode.kt、ToyTravelPlanNode.kt、ToyStudyPlanNode.kt、ToyWrapUpNode.kt - A2A 执行器:
data-agent-backend/src/main/kotlin/io/github/qifan777/server/a2a/ToyAgentExecutor.kt - 前端展示:
data-agent-frontend/src/App.vue - 前端节点卡片:
route-node-card.vue、travel-plan-node-card.vue、study-plan-node-card.vue、wrap-up-node-card.vue
1. 先从整体结构看这次升级
这次提交最核心的变化不是“多了几个类”,而是 Graph 开始具备了明确分工:
ROUTE_NODE负责判断当前输入属于什么场景TRAVEL_PLAN_NODE负责生成旅行方案STUDY_PLAN_NODE负责生成学习计划WRAP_UP_NODE负责把上一步结果整理成最终清单
如果用一句话概括这一版:
一个输入先被分类,再走专属分支,最后回到统一出口。
这已经不是单节点调用模型,而是一个小型编排系统了。
2. ToyGraphSpec 把图里的协议收拢到一处
这次新增了 ToyGraphSpec.kt:
object ToyGraphSpec {
const val NAME = "toy-branch-streaming-graph"
object Node {
const val ROUTE = "ROUTE_NODE"
const val CONFIRM = "CONFIRM_NODE"
const val TRAVEL_PLAN = "TRAVEL_PLAN_NODE"
const val STUDY_PLAN = "STUDY_PLAN_NODE"
const val WRAP_UP = "WRAP_UP_NODE"
}
object StateKey {
const val INPUT = "input"
const val SCENE = "scene"
const val SCENE_LABEL = "sceneLabel"
const val DRAFT = "draft"
const val FINAL_OUTPUT = "finalOutput"
}
object Scene {
const val TRAVEL = "travel"
const val STUDY = "study"
}
}它解决的是一个很实际的问题:
以前如果节点名、状态键、分支值都散落在各个文件里,节点一多就会开始靠记忆维护,特别容易出现下面这些问题:
GraphConfiguration里写的节点名和前端识别的节点名不一致EdgeAction返回的分支值和 mapping 表对不上- 上游写的状态键和下游读取的状态键拼写不一致
所以 ToyGraphSpec 本质上是在声明这张图的“公共协议”。
这里有个细节值得提一下:Node 里已经预留了 CONFIRM_NODE,但这个提交对应的运行链路里还没有真正接入它。当前真正跑起来的是ROUTE / TRAVEL_PLAN / STUDY_PLAN / WRAP_UP 这 4 个节点。
3. GraphConfiguration 真正把单链路改成了分支图
这一版的核心配置是:
return StateGraph(keyStrategyFactory)
.addNode(ToyGraphSpec.Node.ROUTE, AsyncNodeAction.node_async(toySceneRouterNode))
.addNode(ToyGraphSpec.Node.TRAVEL_PLAN, AsyncNodeAction.node_async(toyTravelPlanNode))
.addNode(ToyGraphSpec.Node.STUDY_PLAN, AsyncNodeAction.node_async(toyStudyPlanNode))
.addNode(ToyGraphSpec.Node.WRAP_UP, AsyncNodeAction.node_async(toyWrapUpNode))
.addEdge(StateGraph.START, ToyGraphSpec.Node.ROUTE)
.addConditionalEdges(
ToyGraphSpec.Node.ROUTE,
AsyncEdgeAction.edge_async(toySceneBranchEdge),
mapOf(
ToyGraphSpec.Scene.TRAVEL to ToyGraphSpec.Node.TRAVEL_PLAN,
ToyGraphSpec.Scene.STUDY to ToyGraphSpec.Node.STUDY_PLAN,
),
)
.addEdge(ToyGraphSpec.Node.TRAVEL_PLAN, ToyGraphSpec.Node.WRAP_UP)
.addEdge(ToyGraphSpec.Node.STUDY_PLAN, ToyGraphSpec.Node.WRAP_UP)
.addEdge(ToyGraphSpec.Node.WRAP_UP, StateGraph.END)这段代码可以直接读成一张执行图:
- 从
START进入ROUTE_NODE ROUTE_NODE执行结束后,不是固定走下一步,而是进入条件边- 如果条件边返回
travel,走TRAVEL_PLAN_NODE - 如果条件边返回
study,走STUDY_PLAN_NODE - 无论走哪条分支,最终都汇合到
WRAP_UP_NODE - 收尾后结束
这就是多节点图里最常见的一种形态:
先分流,再汇流。
4. KeyStrategyFactory 让状态更新语义变得明确
这次 StateGraph 不再是直接 new,而是先定义了一套状态策略:
val keyStrategyFactory = KeyStrategyFactory {
mutableMapOf(
ToyGraphSpec.StateKey.INPUT to KeyStrategy.REPLACE,
ToyGraphSpec.StateKey.SCENE to KeyStrategy.REPLACE,
ToyGraphSpec.StateKey.SCENE_LABEL to KeyStrategy.REPLACE,
ToyGraphSpec.StateKey.DRAFT to KeyStrategy.REPLACE,
ToyGraphSpec.StateKey.FINAL_OUTPUT to KeyStrategy.REPLACE,
)
}这意味着这些状态键在图执行过程中都是“覆盖式更新”。
为什么这里要显式写 REPLACE?
因为这几个字段都是天然单值:
input只有一份原始输入scene只有一个路由结果sceneLabel只对应当前命中的场景说明draft只保存当前分支产生的那份草稿finalOutput只保存最终收尾结果
如果不把这些规则讲清楚,图一旦继续扩展,很容易出现“这个字段到底该叠加还是覆盖”的歧义。
5. ToySceneRouterNode 负责决定走哪条分支
路由节点的逻辑非常清晰:
override fun apply(state: OverAllState): Map<String, Any> {
val input = state.value(ToyGraphSpec.StateKey.INPUT, "")
val travelKeywords = listOf("旅游", "旅行", "出游", "攻略", "景点", "酒店", "美食", "周末去哪")
val scene =
if (travelKeywords.any {
input.contains(
it,
ignoreCase = true
)
}) ToyGraphSpec.Scene.TRAVEL else ToyGraphSpec.Scene.STUDY
val sceneLabel = if (scene == ToyGraphSpec.Scene.TRAVEL) "旅行攻略" else "学习计划"
return mapOf(
ToyGraphSpec.StateKey.SCENE to scene,
ToyGraphSpec.StateKey.SCENE_LABEL to sceneLabel,
)
}它做了两件事:
- 根据关键词把输入粗分成
travel或study - 同时写入更适合展示和 Prompt 复用的
sceneLabel
这里的重点不在算法复杂度,而在职责边界:
路由节点只负责判断方向,不负责生成最终内容。
这样后面的业务节点就可以只关注自己的专业输出。
6. ToySceneBranchEdge 只做一件事:把 scene 翻译成下一跳
条件边代码很短:
@Component
class ToySceneBranchEdge : EdgeAction {
override fun apply(state: OverAllState): String {
return state.value(ToyGraphSpec.StateKey.SCENE, ToyGraphSpec.Scene.STUDY)
}
}它本质上就是在说:
- 从状态里读取
scene - 把这个值作为分支 key 返回给
addConditionalEdges(...)
这一层虽然简单,但很关键,因为 Graph 的跳转逻辑并不是写在 Node 里,而是写在 Edge 里。
Node 负责产出状态,Edge 负责根据状态决定去向。
这也是 Graph 编排比“if else 调函数”更清晰的地方:
节点做业务,边做路由。
7. 两个业务分支节点只负责各自领域的流式生成
旅行节点:
val flux = ChatClient.create(chatModel)
.prompt()
.system("你是一个适合教程演示的旅行助手。输出要口语化、结构清晰,分成目的地亮点、半日安排、注意事项三部分。")
.user("请根据这段需求给我一个简短旅行攻略:$input")
.stream()
.chatResponse()
return mapOf(ToyGraphSpec.StateKey.DRAFT to flux)学习节点:
val flux = ChatClient.create(chatModel)
.prompt()
.system("你是一个适合教程演示的学习教练。输出要口语化、结构清晰,分成目标拆解、今日安排、避坑提醒三部分。")
.user("请根据这段需求给我一个简短学习计划:$input")
.stream()
.chatResponse()
return mapOf(ToyGraphSpec.StateKey.DRAFT to flux)这两个节点的结构几乎一样,区别只在 Prompt 角色不同。
这里要重点看懂两件事:
- 两个节点都把输出写到同一个状态键
draft - 节点返回的不是最终字符串,而是模型流
Flux
也就是说,Graph 这时已经开始有了一种“统一接口”的味道:
- 上游不同分支都产出
draft - 下游收尾节点不关心你来自哪条分支
- 只要能从状态里读到
draft,它就能继续处理
这是一种很适合后续扩展的设计。
8. ToyWrapUpNode 把不同分支重新收敛成统一输出
收尾节点是这张图里“汇流”的关键:
val sceneLabel = state.value(ToyGraphSpec.StateKey.SCENE_LABEL, "内容规划")
val draft = state.value(ToyGraphSpec.StateKey.DRAFT, AssistantMessage::class.java).orElseThrow()
val flux = ChatClient.create(chatModel)
.prompt()
.system("你是一个教程里的收尾节点。请把输入整理成更通俗的行动清单,控制在 3 到 5 条,每条一句话。")
.user("请把这份${sceneLabel}整理成用户一看就能执行的清单:${draft.text}")
.stream()
.chatResponse()
return mapOf(ToyGraphSpec.StateKey.FINAL_OUTPUT to flux)这里最值得注意的是这一句:
state.value(ToyGraphSpec.StateKey.DRAFT, AssistantMessage::class.java)虽然上游分支节点返回的是流式 ChatResponse,但当节点执行结束后,Graph 会把可供后续节点继续使用的最终消息收敛进状态。
因此收尾节点可以直接把 draft 当成 AssistantMessage 读取,再继续组装下一轮 Prompt。
这就说明这张图不是“前端拿到流就结束”,而是真正支持:
上游节点流式产出 -> Graph 状态收敛 -> 下游节点继续消费
这也是多节点编排真正开始有价值的地方。
9. ToyAgentExecutor 让 A2A 和 Graph 开始真正对齐
执行器的关键入口是:
val input = ((context.message.parts.first { it is TextPart }) as TextPart).text
stateGraph.compile()
.stream(mapOf(ToyGraphSpec.StateKey.INPUT to input))也就是说,A2A 收到的文本消息被转成了 Graph 的初始状态:
TextPart -> input -> StateGraph
接下来,执行器会逐个消费 Graph 的 NodeOutput,并翻译成前端能识别的 artifact:
GRAPH_NODE_STREAMING时发TextPartGRAPH_NODE_FINISHED时发DataPart- 非流式输出也会发
DataPart
这一层很重要,因为它把 Graph 的内部事件变成了统一的协议事件:
artifact.name对应节点名artifact.parts.text对应节点流式文本artifact.parts.data对应节点完成后的状态快照artifact.metadata.outputType对应当前是流中还是结束
所以前端其实不需要理解 Graph 内部实现,只要理解 artifact 协议就能画出整条时间线。
10. 前端为什么能把每个节点独立显示出来
App.vue 里做了两件核心事情。
第一件,是把节点名映射到组件:
const NODE_COMPONENTS = {
[TOY_GRAPH_NODE.ROUTE]: markRaw(RouteNodeCard),
[TOY_GRAPH_NODE.TRAVEL_PLAN]: markRaw(TravelPlanNodeCard),
[TOY_GRAPH_NODE.STUDY_PLAN]: markRaw(StudyPlanNodeCard),
[TOY_GRAPH_NODE.WRAP_UP]: markRaw(WrapUpNodeCard),
}第二件,是按 artifact 持续更新对应节点内容:
if (artifactName && artifactName in NODE_COMPONENTS) {
const status: ToyStep['status'] =
artifact.metadata?.outputType == 'GRAPH_NODE_FINISHED' ? 'success' : 'pending'
upsertStep(artifactName, text, status, data)
}这样一来,前端就具备了下面这套能力:
- 收到
ROUTE_NODE的输出,就更新路由卡片 - 收到
TRAVEL_PLAN_NODE或STUDY_PLAN_NODE的流,就持续累加到对应分支卡片 - 收到
WRAP_UP_NODE的流,就显示最终整理过程 - 根据
outputType判断当前卡片是“生成中”还是“已完成”
再加上这段排序逻辑:
const order: string[] = [
TOY_GRAPH_NODE.ROUTE,
TOY_GRAPH_NODE.TRAVEL_PLAN,
TOY_GRAPH_NODE.STUDY_PLAN,
TOY_GRAPH_NODE.WRAP_UP,
]整个 Graph 就被展示成一条稳定的节点时间线了。
11. 这次前端卡片设计,实际上在帮助你“看见图”
这次提交新增了 4 个节点卡片组件,每个组件都只负责解释一个节点:
route-node-card.vue展示命中的场景和路由说明travel-plan-node-card.vue展示旅行分支的流式攻略study-plan-node-card.vue展示学习分支的流式计划wrap-up-node-card.vue展示统一收尾后的行动清单
这件事很有价值,因为它把“Graph 编排”从后端概念变成了肉眼可见的执行过程。
你不再只是知道图跑完了,而是能看到:
- 路由先发生
- 只有一条业务分支会真正激活
- 最后一定会回到收尾节点
这对调试和教学都特别友好。
12. 这一版最值得记住的状态流转
如果把整张图压缩成状态视角,可以记成下面这条线:
- A2A 把用户文本写进
input ROUTE_NODE写出scene和sceneLabel- 条件边读取
scene决定进入哪个分支 - 分支节点把结果写进
draft WRAP_UP_NODE读取draft和sceneLabel- 收尾节点产出
finalOutput
这个流转关系比单节点版本强很多,因为它开始形成稳定约定:
- 路由节点负责分类
- 业务节点负责生成草稿
- 收尾节点负责最终交付
只要这个约定不变,你后面继续加分支、加人工确认、加重试节点,整体都还能保持清晰。
13. 这一章应该怎么验证
建议直接用两类输入测试:
- 旅行类输入,例如“帮我做一个杭州周末旅行攻略,想吃本地美食”
- 学习类输入,例如“我想两周内入门 Python,请给我一个学习计划”
你应该能观察到:
- 两种输入都会先经过
ROUTE_NODE - 旅行输入只会激活
TRAVEL_PLAN_NODE - 学习输入只会激活
STUDY_PLAN_NODE - 两种输入最后都会进入
WRAP_UP_NODE - 前端时间线会随着流式输出持续增长
如果这 5 点都能看到,就说明“多节点分支图 + 前端可视化”已经跑通了。
常见问题
1) 为什么要拆成路由节点和业务节点,而不是一个节点里写 if else
因为节点职责拆开后,图结构更清晰,也更容易扩展。后面你要加新分支时,只需要补节点和边,不用把所有逻辑塞回一个大节点里。
2) 为什么旅行节点和学习节点都写 draft
因为这样收尾节点只需要认一种输入接口,不需要分别处理 travelDraft 和 studyDraft。
3) 为什么 WRAP_UP_NODE 还能继续消费上游流式结果
因为 Graph 在节点执行完成后,会把后续可消费的最终状态收敛下来。所以下游节点读取到的是稳定状态,而不是原始流对象本身。
4) ToyGraphSpec 里为什么已经有 CONFIRM_NODE
这是一个提前预留的常量,但这个提交对应的实际运行图还没有接它。当前章节应该以“双分支 + 收尾”的实际链路来理解。
本章完成标准
读完这一篇,你至少应该能解释清楚这 4 件事:
- 单节点 Graph 是怎么升级成多节点分支图的
addConditionalEdges(...)是如何驱动分支跳转的- 为什么不同业务分支可以通过统一的
draft状态和收尾节点协作 - 前端为什么能按节点名把整个执行过程可视化出来
如果把这一章压缩成一句话,可以记成:
上一章让 Graph 跑起来,这一章让 Graph 开始像一张真正的流程图。